Wrike Datahub
A new structured data layer powering scalable operations inside Wrike’s work management platform.
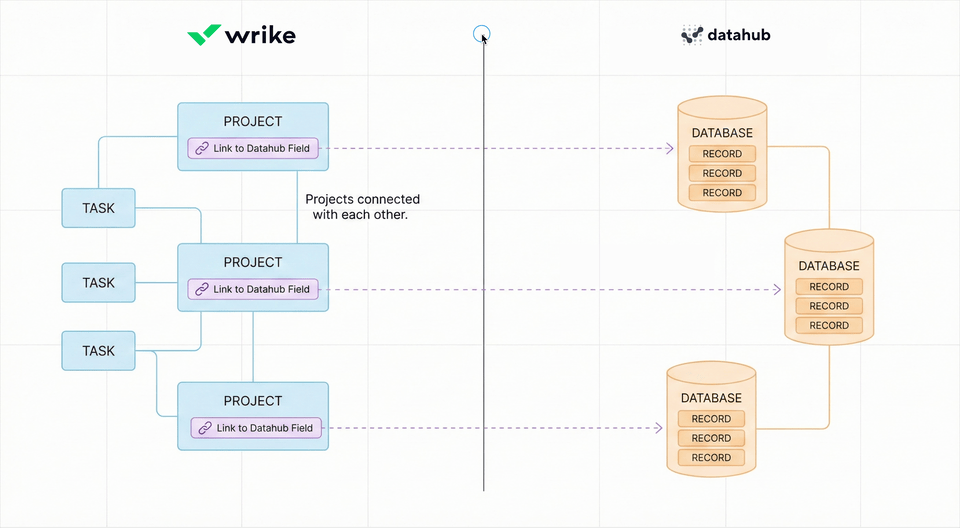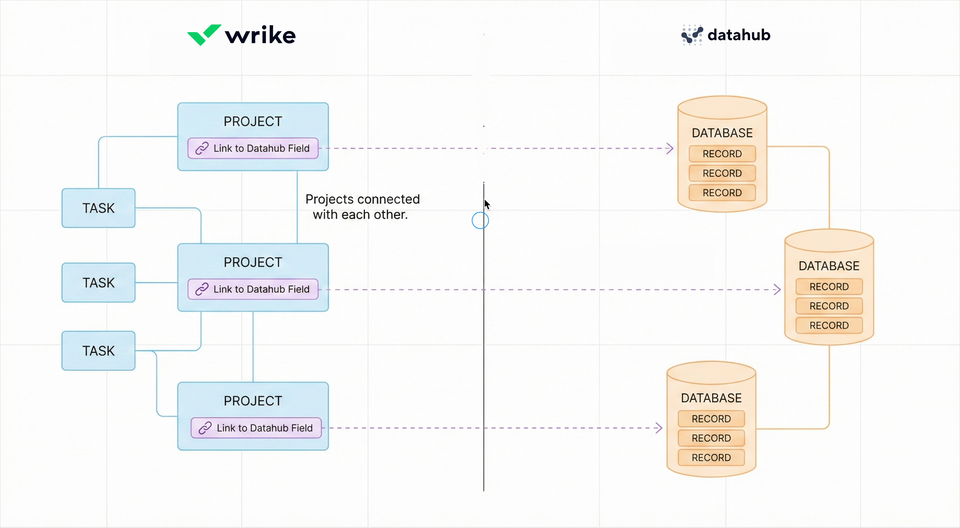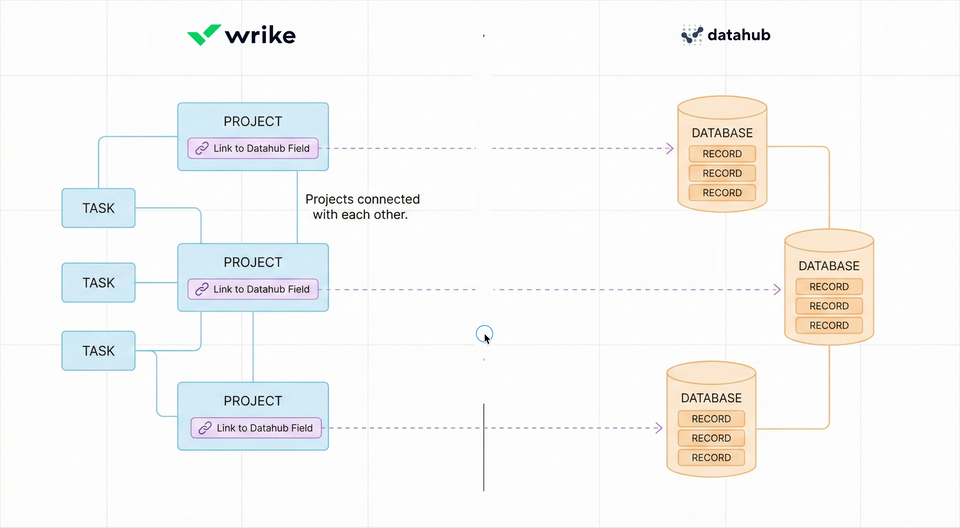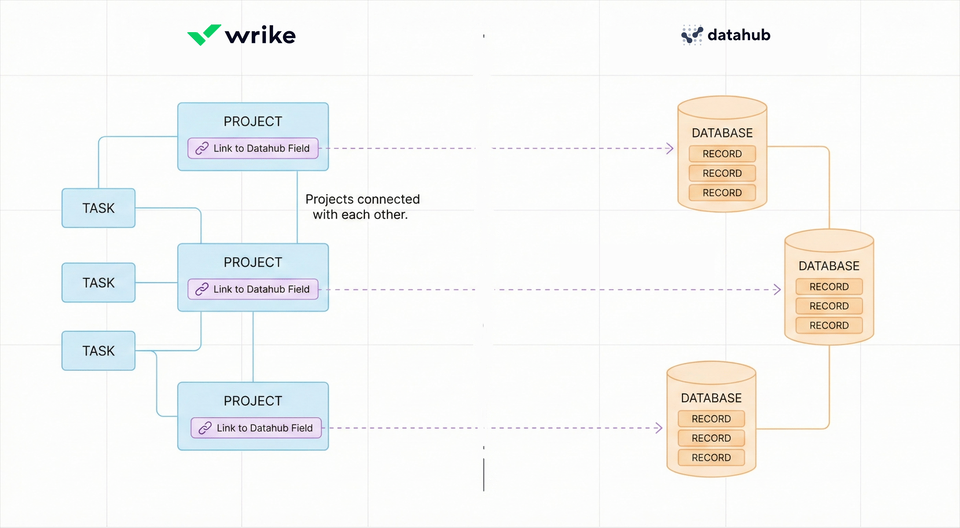
In practice it means users can add custom properties to Wrike tasks that pull live data from external databases, all managed in one place.
691
active customer accounts in the first quarter
550K+
records created within the first quarter
34%
My contribution: I helped to gather and shape early research insights into a clear direction, owned UX exploration and UI design, enabled prototype development, and influenced key scope and naming decisions that became foundational to Datahub’s MVP.
UX design
39%
month-over-month adoption growth
of accounts with access created databases
User interviews
Prototyping
Animation credit: Wrike’s marketing team
The Challenge
Validate the use-cases, and the demand, and find a way to introduce a new data management model into an existing complicated product.
Context:
Wrike already had a robust work graph platform but we had been hearing from customers that they needed a way to connect their work with structured data: inventories, assets, datasets, reference objects, and domain-specific records.
The industries we had been hearing from:
industrial manufacturing
pharma testing subcontractors
operations-heavy teams
service organizations
Each relied on spreadsheets or external databases to manage critical objects: equipment, tests, materials, tickets, but needed them connected to daily work inside Wrike.
Datahub’s mission:
Build a data management vertical that could:
support far larger numbers of records than Wrike’s core model
allow use of industry-specific vocabularies
connect data records with work items (tasks, projects)
act as the foundation for new automation layers and reporting
Wrike’s goal was to extend its work graph with a serviceable data layer, and to let work and data coexist and reinforce each other.
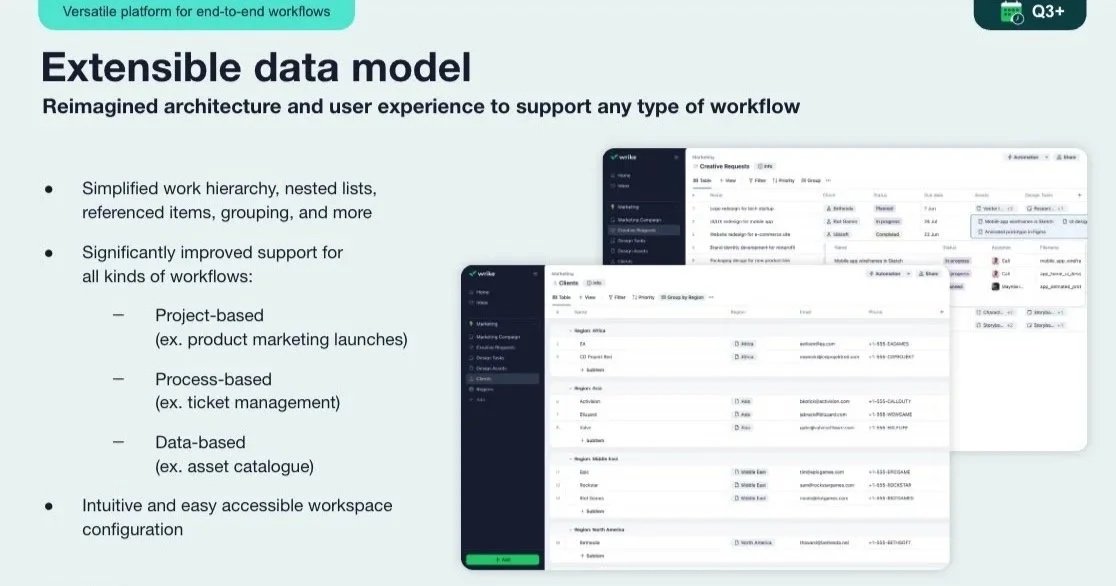
My Role & Approach
I collaborated with product, engineering, and research teams to connect customer insights with technical capabilities, ensuring we built solutions that addressed user needs.
Working with the PM: I helped synthesize user feedback into actionable insights, suggested prioritization, and created sales enablement artifacts to help the business communicate what we were building.
Working with developers: I focused on scope discussions and enablement: what's technically feasible given our timeline, where could we simplify without losing core value.
Working with researchers:
Naming and value prop research helped us position Datahub within Wrike's ecosystem after the pivot
MVP functionality research (customer council interviews, surveys, and targeted follow-ups) validated what features were truly essential
Active user feedback gathering shaped our post-launch iteration priorities

Discovery
Throughout the discovery process, my task was to help build whatever artifacts we needed for the concept tests, usability tests, observational tests, copy & naming tests.
I also made sure to attend as many interviews as possible, and conduct some of them.
1. Validating use-cases
With the help of our UXR partner, we started conversations with some of the interested Wrike customers.
First, we just showed them a single slide with the outline of our offer and asked them if that’s something they find interesting.
Later on, we launched a survey to get some qualitative data to support or disprove our findings.
Bottom line, we gathered enough to invest more.
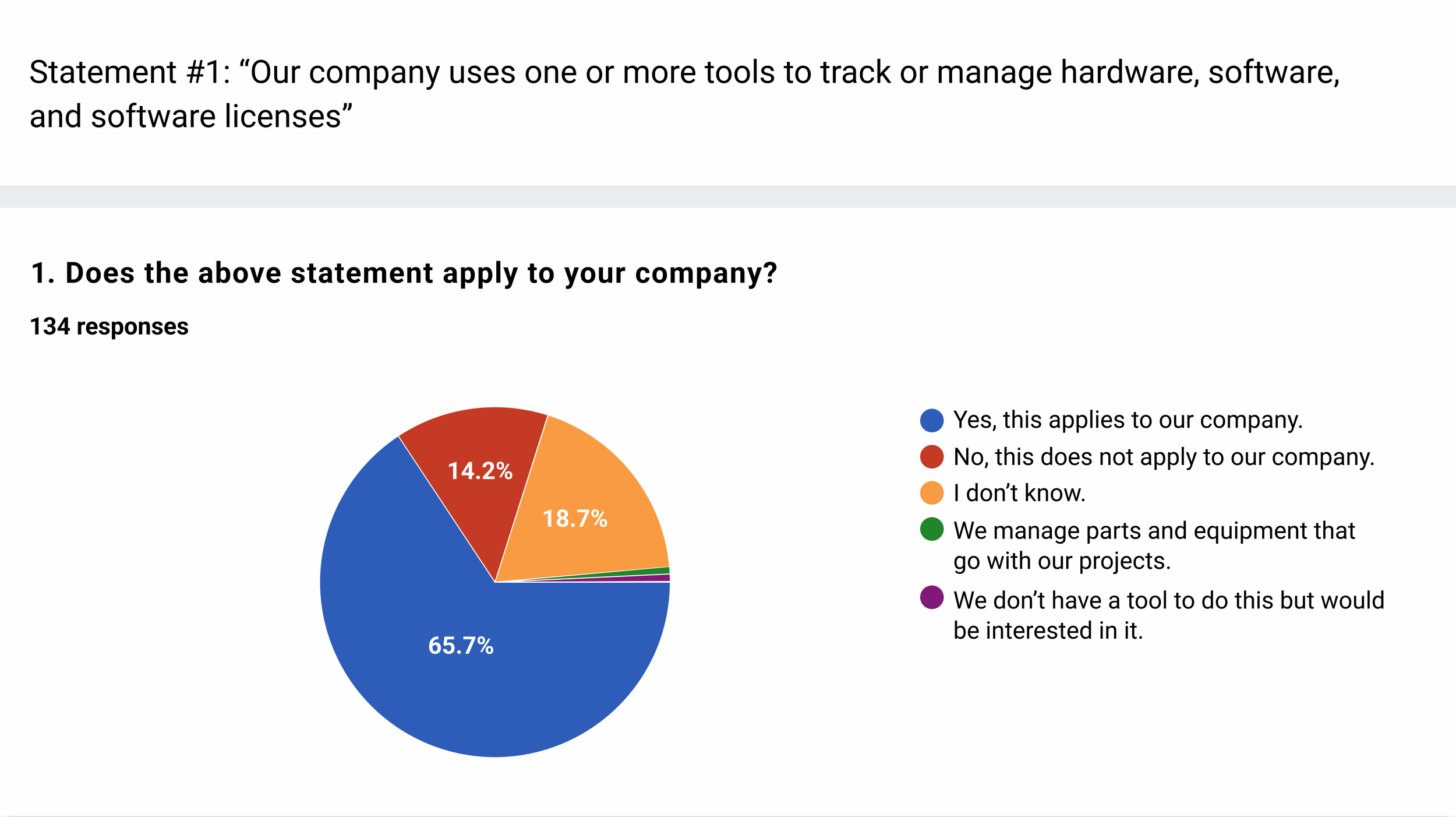
At this stage we needed to see if the positioning we had in mind resonated with our real and potential customers.
We opted for an approach with a set of landing pages that described Datahub, its value, and its feature set.
We wanted to hear the conceptual understanding of the product told back to us by our customers. It was also helpful for us to understand the vocabulary for the product’s UI and what branding directions would be more promising (the name “Datahub” wasn’t settled on yet).
I produced the landing pages, and conducted some of the interviews.
2. Validating our offering
3. Validating the prototype
With more reassurance we continued to raise the fidelity of what we were presenting in the interviews.
Without spending the development resources the design engineer who was helping us out on the project and I created a prototype that showed the core interaction of Datahub: attaching a database record to a Wrike task.
The eventual outcome: the project was greenlit and we moved to the MVP development.
Execution
At the execution, phase the bulk of my work was feature prioritization together with the PM, and figuring out the scope and the technical feasibility in conversations with the developers.
Story 1: Building the MVP
Import: build vs. buy vs. reuse
Data import was essential to quickly onboard users and their data.
We faced a trade-off between three options:
Reuse Wrike's existing import functionality. Extra tie-in with the “mothership”, but the implementation wasn't well-suited for our needs
Partner with an external solution. Robust feature set, but collaboration with an entity that has its own roadmap
Build something quick and nimble. Bypass all the complications, but spend development time.
We chose option three. It took us less time to build it than it would have taken to negotiate and align on the other options.
At that point, we could afford to act like that—the "integration directive" hadn't arrived yet, and we optimized for speed and customer preparedness.


Entry point: Designing for flexibility
Datahub started as a very separate tool from Wrike’s main work environment. However, at this point we already started the conversations about a potential close integration with the main product.
So the first entry point we chose had to account for this uncertainty, and be implemented so as not to slow us down, but also not to be expensive should we change it in the future.
Once the winds changed, we had to cycle through a variety of more established entry points used by other Wrike tools.
This meant discussions with the larger design team, multiple design reviews, alignment sessions.
Naming: Databases that aren't databases
Technically, Wrike Datahub's "databases" are single tables that can be connected to other tables. Not really databases as engineers would understand them.
But we observed how customers talked about their needs, considered the marketing angle, and opted to call them "databases."
This met understandable resistance from the devs. They weren't wrong. But we made the case that customer language trumps technical precision here, and they were eventually convinced.




Strategic change mid-project
The initial approach positioned Datahub as a relatively independent solution, separate from Wrike's core platform.
Mid-project, the strategy shifted. Wrike decided to double down on its core strength: deep integration of various work management tools. Datahub would no longer be a separate app, but deeply woven into the Wrike experience.
The pivot happened around 4-5 months into development, as we prepared the first customer betas. It cascaded into design questions:
Where are the entry points now?
How do we name and position this within Wrike?
What's the monetization strategy?
How do we build for deep integration while maintaining a coherent MVP?
Story 2: Improving Main Components
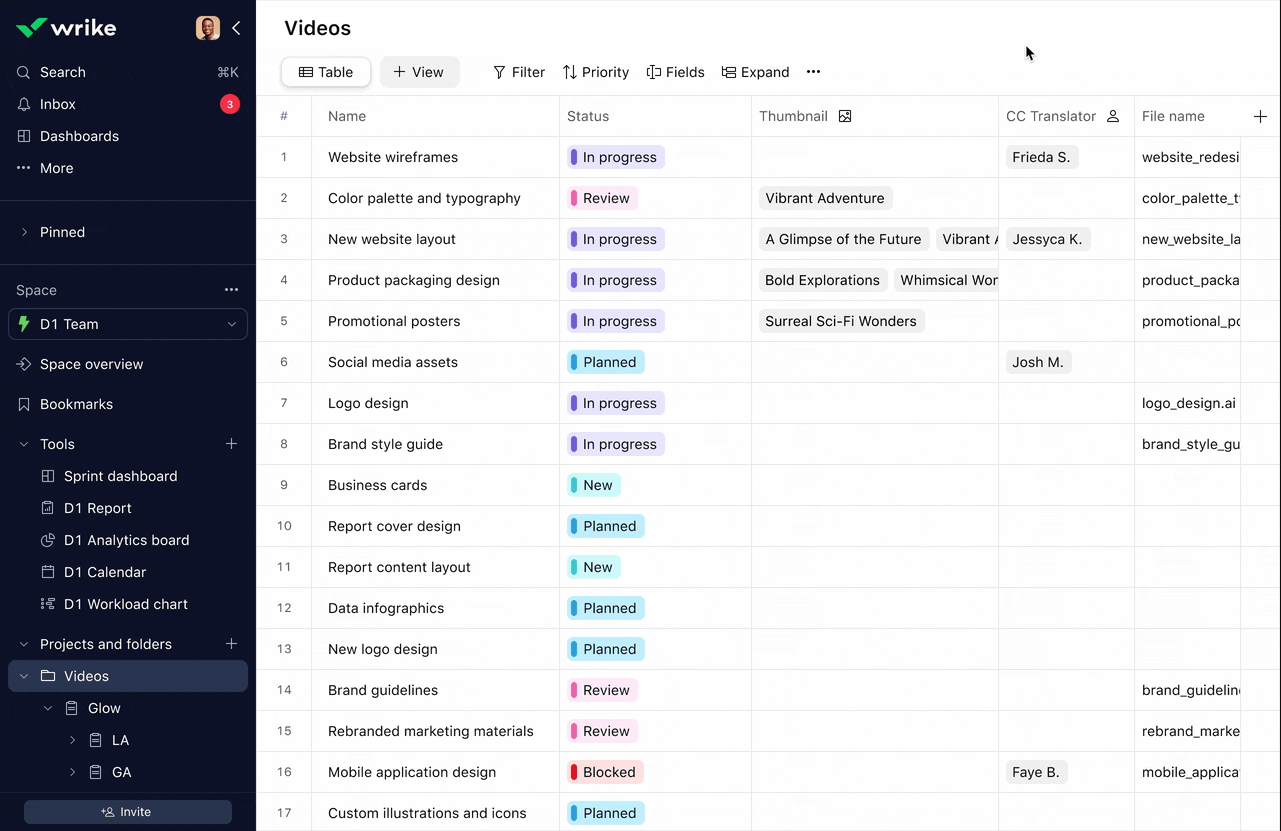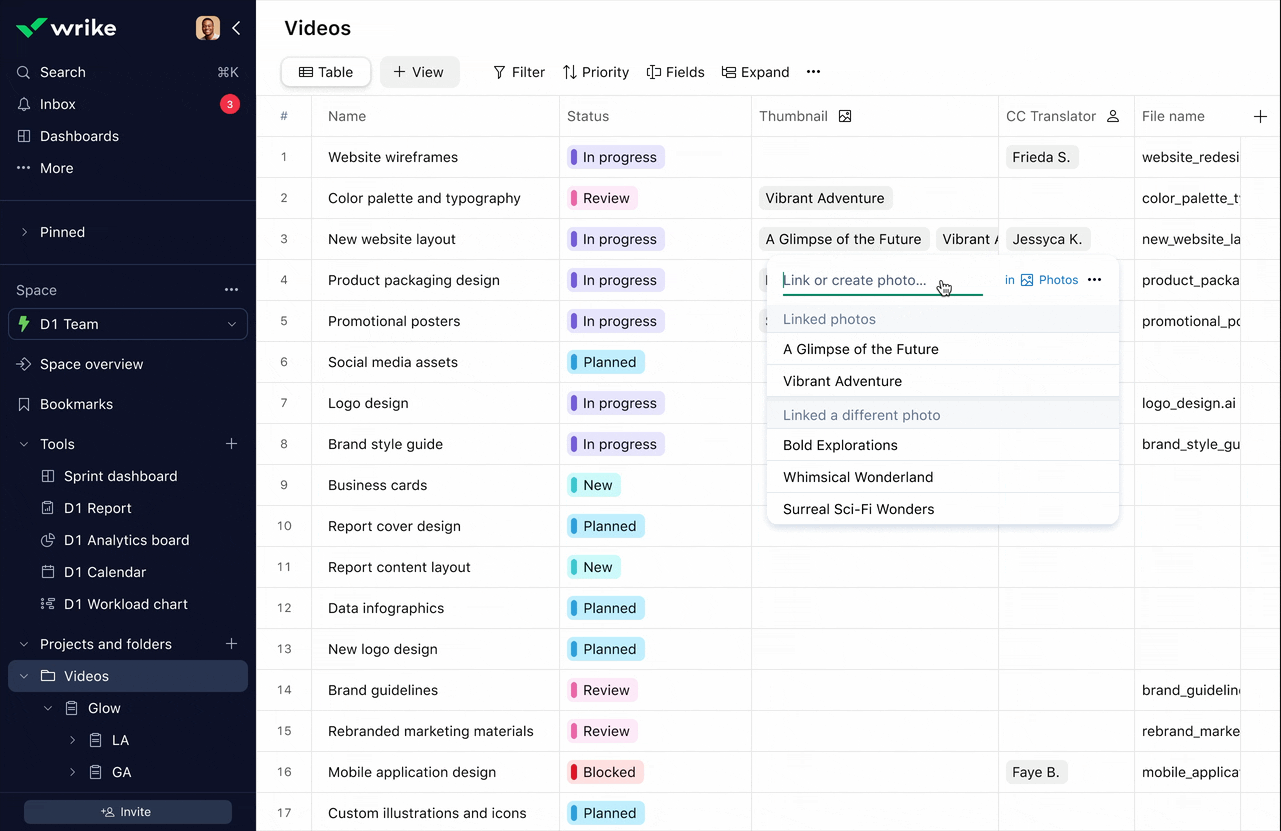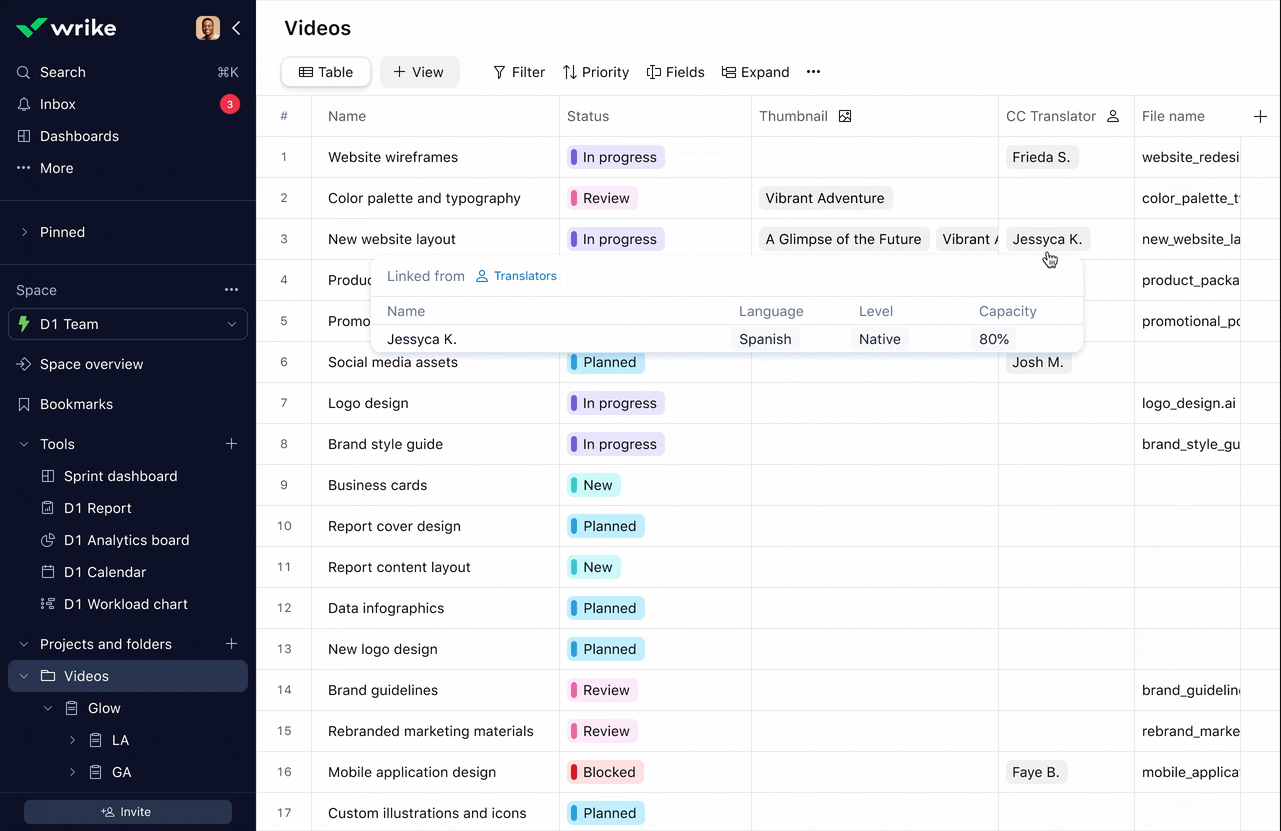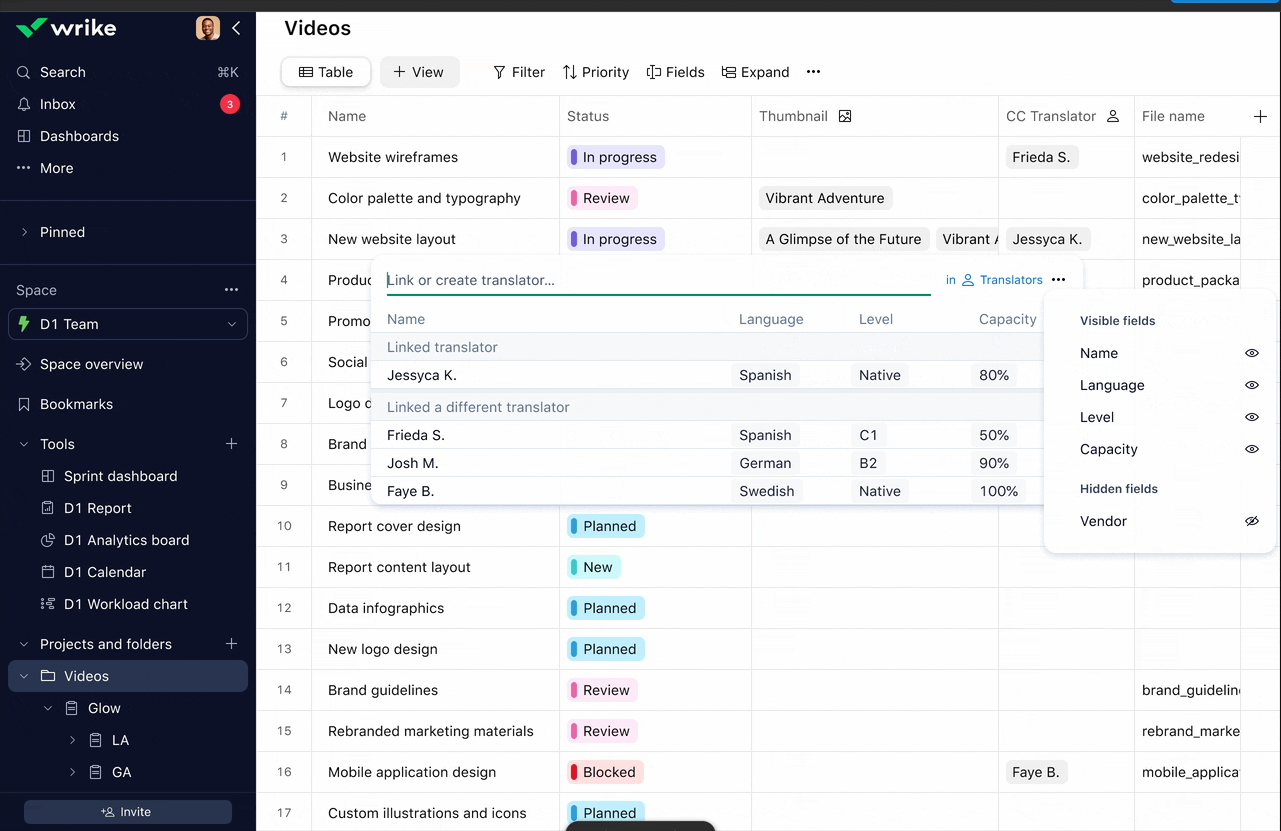
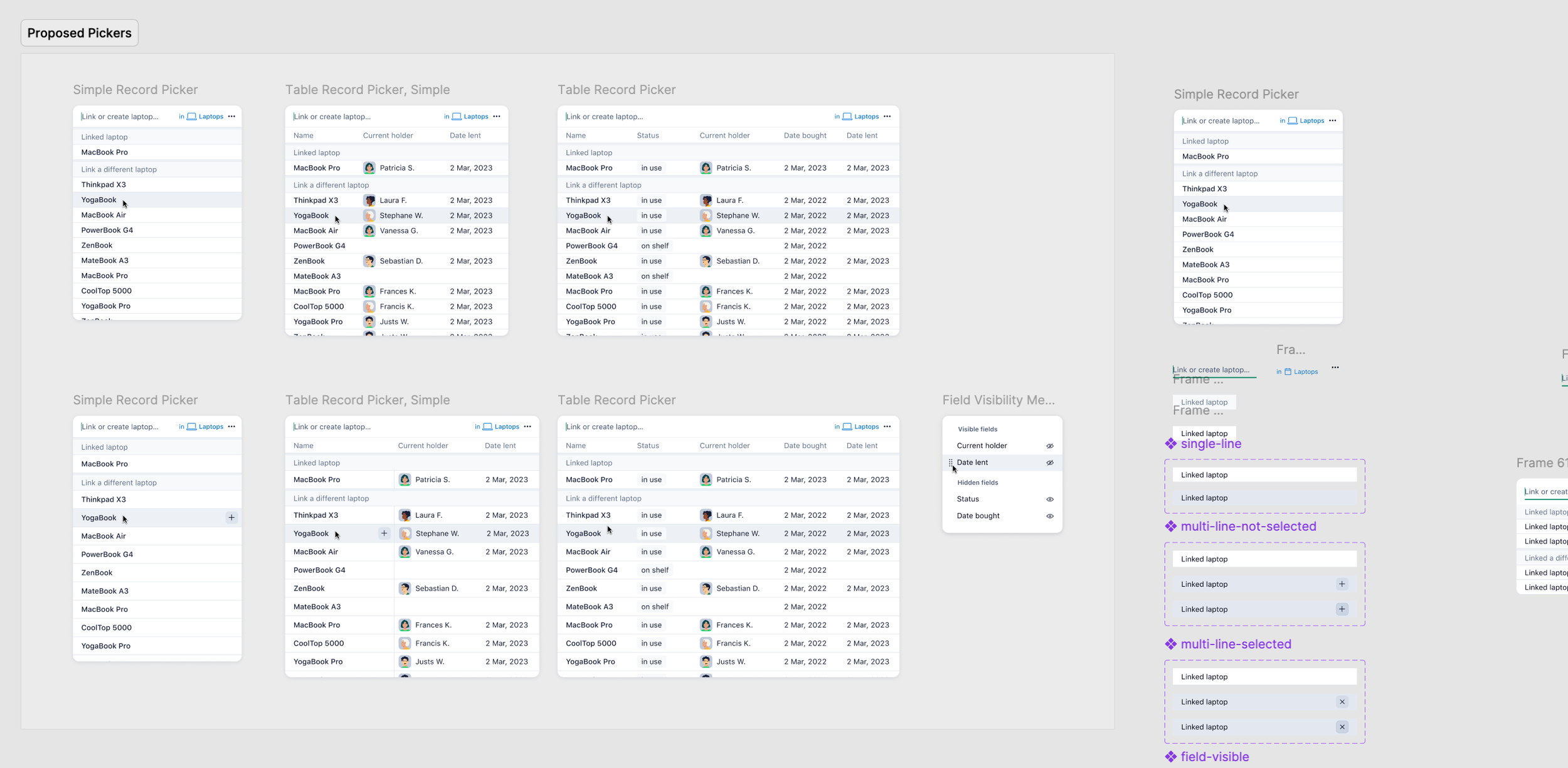
Picker: Function over form, and it stayed that way
The MVP record picker was purely functional: it worked, but it wasn't pretty. I wanted to bring better UI design to it, and more importantly, there was a clear functional gap: users wanted control over which record properties they saw in the picker.
Different roles using the same table needed different information to make decisions. They needed to balance screen real estate with the data they actually used to choose records.
Here's the tension: the picker is basically the face of the product. It's what users interact with constantly. But the scenarios that handle truly large amounts of data, one of Datahub's main benefits, don't actually require much UI. They're bulk operations, imports, API usage.
In the end, the picker lost the prioritization battle to more robust performance and raising data limits, even though we had designed and estimated a better version. The business chose scale over polish at that moment.
Impact & Results
Business impact
The data validated enough demand for Wrike to productize Datahub into a paid add-on. It helped close new deals and upsell existing customers to larger contracts. The monetary goal attached to the launch was met.
More importantly, it proved that Wrike could expand beyond pure work management into adjacent territory, opening up a new revenue stream and competitive positioning.
The research insights, particularly around personalization, directly shaped the post-launch roadmap.
691
active customer accounts in the first quarter
550K+
records created within the first quarter
34%
39%
month-over-month adoption growth
of accounts with access created databases
Reflections
What worked
Building for flexibility paid off. Keeping in mind that the direction might change was uncomfortable, but it's what allowed us to pivot without starting over. When the integration direction won out, we had options instead of confusion.
Research embedded in decisions, not separate from them. Every research activity informed a choice we had to make—naming, prioritization, feature scope.
Cross-functional partnership over hero design. The PM had business context I didn't have. Developers understood technical constraints I couldn't see. The architects knew Wrike's systems better than I did. And it’s absolutely fine.
What I'd do differently
Fight harder for certain craft decisions earlier. The picker redesign was deprioritized for good reasons: performance and scale mattered more. But I think there was a chance to at least win the resources for some of the most essential features.
Document the "why" better during the pivot. We made a lot of rapid decisions when the strategy shifted. Some of that reasoning lives in Slack threads and meeting notes. Future teams inheriting this work would benefit from a clearer record of what we considered and why we chose what we did.